


出品 | 搜狐科技
作者 | 梁昌均
一款国产开源大模型,最近在国内外AI界出圈。
“这是在资源受限的情况下,对研究和工程的一次令人印象深刻的展示。”AI大神、OpenAI创始成员Andrej Karpathy(安德烈·卡帕西)发文称,会仔细阅读这篇非常棒的技术论文。
他提到的这篇论文,用53页的篇幅介绍了一款开源大模型DeepSeek-V3,其由国内AI公司DeepSeek(深度求索)研发推出。
“综合评估表明,DeepSeek-V3已成为目前最强大的开源模型,性能可与GPT-4o和 Claude-3.5-Sonnet等领先的闭源模型相媲美。”该论文表示。
不止安德烈,多位AI大牛,如阿里前副总裁贾扬清、MetaAI科学家田渊栋、英伟达高级研究科学家Jim Fan等,纷纷对这款模型点赞。
有网友认为这是“全球最佳开源大模型”,甚至认为这将推动AGI将比预期更早且能以更低成本实现。
让这些AI大牛点赞的更大原因在于,这款模型仅用了2000多张GPU、训练成本不到600万美元,远远低于OpenAI、Meta等在万卡规模上训练的模型成本。
此前,大模型被认为是需要依靠Scaling Law而迭代演进,但现在这家低调的中国公司可能提供了另一种可能。最近,小米雷军亲自挖95后天才,也让这家公司受到更多关注。
媲美全球最强模型,训练成本仅有GPT-4o的1/18
DeepSeek-V3是一款自研的MoE(混合专家架构)模型,参数规模从前代的2360亿提升到6710亿,在14.8 T tokens上进行了预训练,上下文长度为128K。
评测结果显示,DeepSeek-V3的性能已经成为目前最强大的开源模型,同时在多个主流评测基准上可媲美目前最强大的闭源模型,特别是在代码和数学方面。
在知识能力方面,DeepSeek-V3在MMLU-Pro(综合学科增强版)和GPQA-Diamond(化学、物理和生物)等基准测试超越阿里、Meta等所有开源模型,并领先GPT-4o,但不及Claude-3.5-Sonnet。
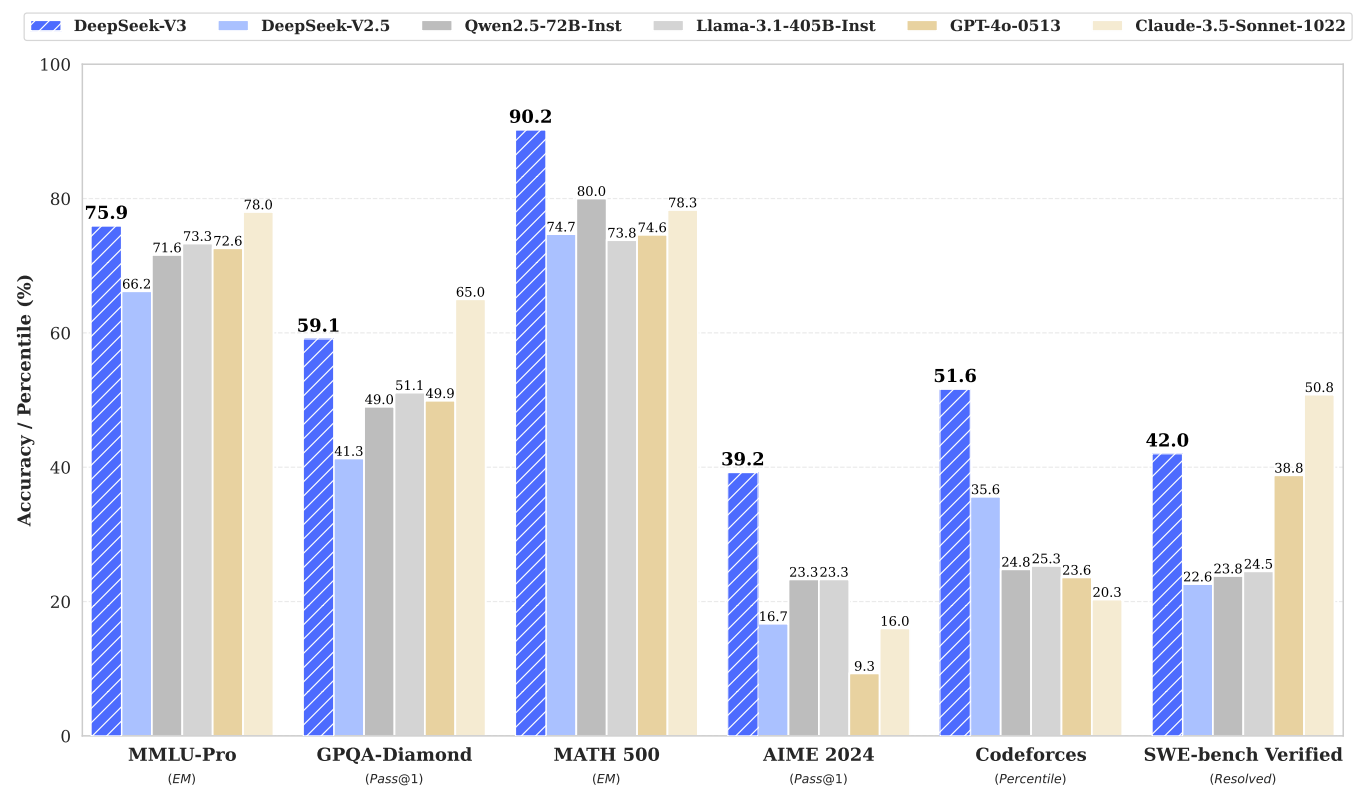
在数学、代码和推理能力方面,DeepSeek-V3在MATH500、AIME2024及Codeforces等多个主流基准测试中,不仅碾压阿里和Meta的最新开源模型,同时超越GPT-4o和Claude-3.5-Sonnet。
深度求索还提到,DeepSeek-V3甚至还在特定基准测试上超过强化推理能力的o1-preview(预览版),如MATH-500,展示其出强大的数学推理能力。
不过,OpenAI早前发布的o1正式版依然是科学、数学和编码等推理领域的王者。在GPQA-Diamond等多个基准评测上,DeepSeek-V3与o1相比均存在明显差距。
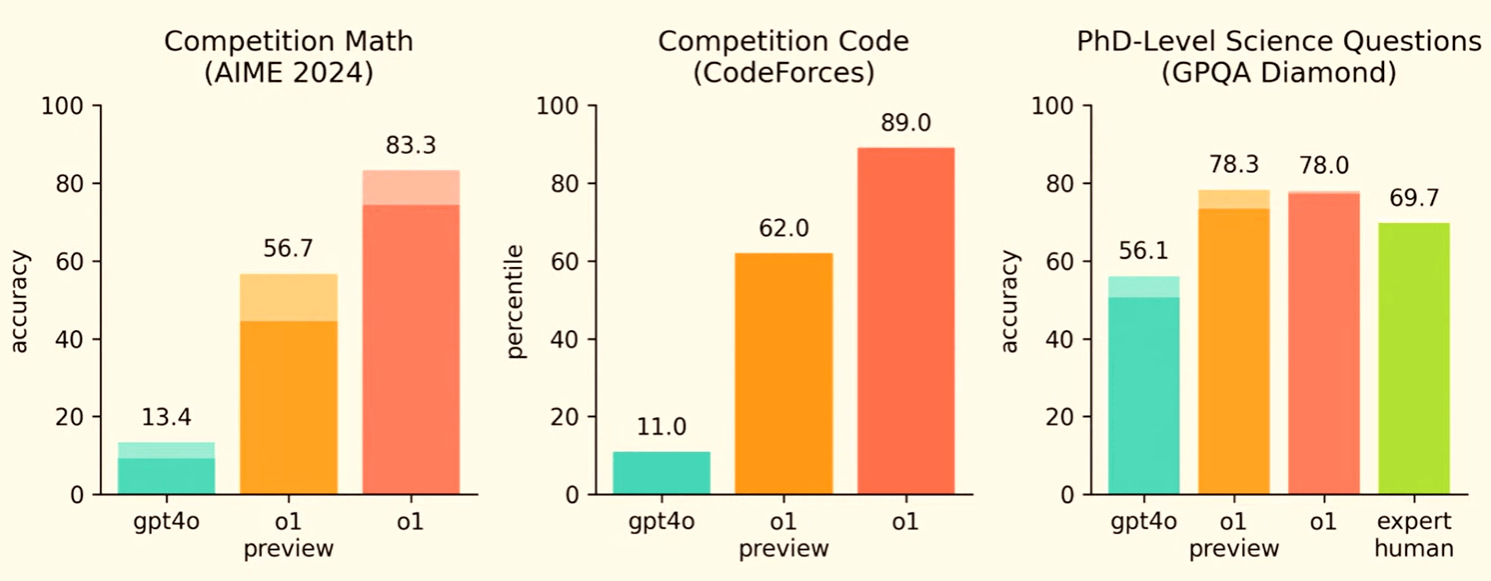
此前,业内不少观点认为,开源模型无法追赶闭源模型。但开源的DeepSeek-V3则证明,开源和闭源模型的差距可以缩小,并完全有希望超越闭源模型。
不过,真正引起一众AI大牛赞叹的是,DeepSeek-V3训练成本竟然只用了不到600万美元——准确说是557.6万美元。该模型在由2048块H800组成的GPU集群上训练3.7天,预训练耗时不到两个月就完成,完整训练仅用了278.8万GPU小时。
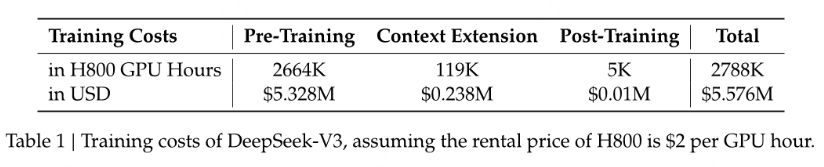
不过,深度求索强调,该成本仅包括DeepSeek-V3的官方训练,不包括先前与架构、算法或数据的有关研究和消融实验相关成本。
安德烈用“a joke of a budget”(玩笑般的预算)表达了对成本的惊讶。他提到,Llama-3-405B的训练耗时3080万个GPU小时,而DeepSeek-V3看起来是一个更强大的模型,但用了不到280万个GPU小时,这意味计算量仅有Llama-3-405B的1/11。
公开信息显示,Llama-3-405B是在近1.64万块H100 GPU集群上训练,预训练时间为54天,耗时超过2118万GPU小时,成本超过5460万美元,是DeepSeek-V3的10倍多。
此外,类似GPT-4o、Claude-3这样的模型则是在数万块GPU上训练,成本均高达1亿美元,是DeepSeek-V3成本的近18倍。
“这是疯狂的效率,难以置信的进步。”不少网友评价称。Meta AI科学家田渊栋也表示,这是令人赞叹的H800黑客技术,是一项了不起的工作。
不过,需要指出的是,DeepSeek-V3还存在一些局限性,比如英文能力还落后于GPT-4o和Claude-Sonnet-3.5,同时部署要求较高,对小型团队不太友好,且生成速度还有提升潜力。
“我真没法跑,没那么多卡。”有AI博主对搜狐科技提到,FP8框架的模型,磁盘都需要接近1T。“对很多人来说,可能连下载动力都没有。”
DeepSeek在论文中表示,随着更先进硬件的开发,这些局限性有望得到解决。
架构+工程组合创新的胜利,大模型或不再仅靠堆算力
为何DeepSeek-V3能用如此低的成本,训练出可以媲美OpenAI、Meta的最强开闭源模型?
一位从事AI算法工程师对搜狐科技表示,DeepSeek在论文中介绍了在模型架构、训练框架、推理部署、硬件设计、数据构建等方面都进行了组合式的工程创新,提出了很多节约算力、提升效率的策略,并保证了模型效果。
深度求索也在论文中强调,这是基于优化算法、框架和硬件的共同设计而实现。
搜狐科技梳理论文了解到,架构方面,DeepSeek-V3依然基于Transformer框架,但采用了MLA(多头潜在注意力)和独创的DeepSeekMoE(混合专家架构),共同推动了算力成本的下降,这两项创新已在DeepSeek-V2中得到验证。
前述工程师还提到,DeepSeek-V3设计了FP8混合精度训练框架,并验证了可行性和有效性,此前主流选择框架是BF16,这可以说是比较大的突破。同时,通信、内存、硬件等方面也进行了算法设计和协同优化。
此外,DeepSeek-V3还在训练语料库中提高了数学和编程样本的比例,扩展了多语言覆盖范围,在后训练阶段使用了模型生成的数据,并利用强化学习的奖励机制,从而提升了模型性能,尤其是推理能力。
不过,有用户发现,DeepSeek-V3对自己的身份认知出现了错误,称自己是OpenAI创造的模型,引发套壳质疑。业内观点认为,这是由于采用了模型生成的受到污染的训练语料导致。
可以说,DeepSeek-V3持续出圈,是一次架构+工程组合创新的胜利。
贾扬清认为,这是智慧和实用主义在发挥作用:在计算人力限制下,用聪明的研究产生最好的结果。“就像Alex Krizhevsky用2个GPU,而不是超级计算机群,创造出奇迹的AlexNet一样。
英伟达高级研究科学家Jim Fan也提到,资源限制是一件美好的事情,在残酷的AI竞争环境中,生存本能是取得突破的主要动力。
这也引发了对“算力决定论”的质疑,是否意味着前沿大模型不再需要大型GPU集群?
“并不是,但你必须确保不会浪费你所拥有的。但这看起来是一个很好的证明,表明在数据和算法方面还有很多事情要做。”安德烈表示。
有观点认为,这标志着向更精益、更具成本效益的AI开发的转变,通过对底层架构和模型流程的优化,证明了优化算法的发展潜力绝不弱于堆算力。
手握万张GPU储备,“95后天才”刚被雷军挖走
DeepSeek-V3的出圈也让背后公司DeepSeek进一步获得关注。
这家公司位于杭州,成立于2023年7月,创始人是颇为低调的80后梁文锋。他更多为投资圈熟知——量化私募四巨头之一幻方的实控人。
梁文锋本硕就读于浙江大学,学的是电子工程系AI方向。后来,他主要在量化投资领域进行研究,2015年创立幻方量化,其一度成为规模超千亿的量化私募巨头。
据36氪,幻方量化早在2019年就成立了AI团队,为自研的深度学习训练平台萤火投资了十多亿元,是国内除大厂以外少数拥有上万张GPU储备的公司。
随着2023年大模型浪潮爆发,梁文锋把幻方做大模型的团队独立为DeepSeek。但在当时众多创业大佬的光环下,DeepSeek还显得籍籍无名。
直到今年5月,DeepSeek-V2模型开源,并掀起一场持续至今的大模型价格战。因此,DeepSeek被冠以“大模型界拼多多”,并在硅谷成为“神秘的东方力量”。
梁文锋此前在为数不多的采访中强调,DeepSeek追求的是AGI,且不做垂类和应用,短期内也不会融资,“研究和技术创新永远是第一优先级”。
同时,他也非常认可开源的价值,“即使OpenAI闭源,也无法阻止被别人赶超”,希望通过开源,走到技术的前沿,参与到全球创新的浪潮里去,而不是趁机赚一笔。
“可能是2年、5年或10年,总之会在我们有生之年实现。”梁文锋同样信仰AGI,为此押注了自然语言、数学和代码和多模态三个方向。
这也让外界看到了这家公司的人才和创新理念。梁文锋此前表示,公司核心技术岗位基本以应届和毕业一两年的人为主,并尽可能少干预管理,让每个人有自由发挥的空间和试错机会。
DeepSeek-V3论文在最后就列出了约200位贡献者,包括150位研发和工程人员,30多位数据标注人员和18位商业合规人员。

值得注意的是,名单依然写上了10位员工离职,包括最近引发关注的“95后天才”罗福莉。消息称,她已入职小米领导大模型团队,由雷军亲自下场挖人,薪酬或在千万元级别。
罗福莉硕士毕业于北京大学计算语言学研究所,毕业后顶着国际顶会ACL 8篇论文作者的光环加入阿里达摩院,2022年加入幻方量化,后转入DeepSeek参与了DeepSeek-V2的研发。
她曾在社交平台回答“阻碍国内团队研究ChatGPT的障碍”时表示,赞同大家提到的缺乏远见者,但个人认为国内非常缺乏工程型的AI实验室。
“这不是把一堆学术背景好的研发人才放在一起,就能干好的事情,大型工程设计才是核心,目标设定,训练调试,评测反馈,交互体验,数据回流,每一步都需要扎得很深。”
罗福莉还在DeepSeek-V2开源后表示,这是群体智慧的结晶,而做到兼顾模型效果和成本,基本纯靠模型结构创新(MLA+DeepSeekMoE)+超强Infra,“创新力就是第一生产力”。
如今,DeepSeek-V3的进一步出圈,无疑为大模型的发展路径提供了新的可能,并再次验证创新才是实现技术理想的关键。
 微信扫一扫打赏
微信扫一扫打赏
 支付宝扫一扫打赏
支付宝扫一扫打赏






